目錄
數據準備
import pandas as pd df = pd.DataFrame([['ABC','Good',1], ['FJZ',None,2], ['FOC','Good',None] ],columns=['Site','Remark','Quantity'])
df

注意:上述Remark字段中得數據類型為字符串str類型,空值取值為'None',Quantity字段中得數據類型為數值型,空值取值為nan
1.篩選指定單列中有空值得數據行
# 語法df[pd.isnull(df[col])]df[df[col].isnull()]
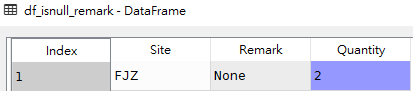
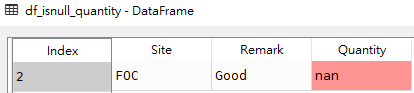
# 獲取Remark字段為None得行df_isnull_remark = df[df['Remark'].isnull()]# 獲取Quantity字段為None得行df_isnull_quantity = df[df['Quantity'].isnull()]
df_isnull_remark
df_isnull_quantity
提示
篩選指定單列中沒有空值得數據行
# 語法df[pd.notnull(df[col])]df[df[col].notnull()]
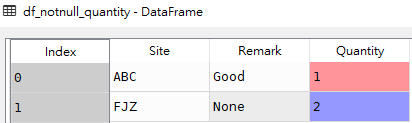
# 獲取Remark字段為非None得行df_notnull_remark = df[df['Remark'].notnull()]# 獲取Quantity字段為非None得行df_notnull_quantity = df[df['Quantity'].notnull()]
df_notnull_remark

df_notnull_quantity
2.篩選指定多列中/全部列中滿足所有列有空值得數據行
# 語法df[df[[cols]].isnull().all(axis=1)] df[pd.isnull(df[[cols]]).all(axis=1)]
在df基礎上增加一行生成df1
df1 = pd.DataFrame([['ABC','Good',1], ['FJZ',None,2], ['FOC','Good',None], [None,None,None] ],columns=['Site','Remark','Quantity'])

# 獲取df1所有列有空值得數據行 all_df_isnull = df1[df1[['Site','Remark','Quantity']].isnull().all(axis=1)]
all_df_isnull

提示
篩選指定多列中/全部列中滿足所有列沒有空值得數據行
# 語法df[df[[cols]].notnull().all(axis=1)] df[pd.notnull(df[[cols]]).all(axis=1)]
# 獲取df1所有列沒有空值得數據行 all_df_notnull = df1[df1[['Site','Remark','Quantity']].notnull().all(axis=1)]
all_df_notnull

3.篩選指定多列中/全部列中滿足任意一列有空值得數據行
# 語法df[df[[cols]].isnull().any(axis=1)] df[pd.isnull(df[[cols]]).any(axis=1)]
df1(數據源)

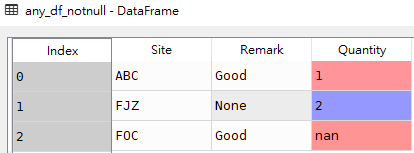
# 獲取df1所有列中滿足任意一列有空值得數據行 any_df_isnull = df1[df1[['Site','Remark','Quantity']].isnull().any(axis=1)]
any_df_isnull

提示
篩選指定多列中/全部列中滿足任意一列沒有空值得數據行
# 語法df[df[[cols]].notnull().any(axis=1)] df[pd.notnull(df[[cols]]).any(axis=1)]
# 獲取df1所有列中滿足任意一列沒有空值得數據行 any_df_notnull = df1[df1[['Site','Remark','Quantity']].notnull().any(axis=1)]
any_df_notnull
Numpy里邊查找NaN值得話,使用np.isnan()
Pabdas里邊查找NaN值得話,使用.isna()或.isnull()
import pandas as pdimport numpy as np df = pd.DataFrame({'site1': ['a', 'b', 'c', ''], 'site2': ['a', np.nan, '', 'd'], 'site3': ['a', 'b', 'c', 'd']})df

df['contact_site'] = df['site1'] + df['site2'] + df['site3']
新增數據列后得df

res1 = df[df['site2'].isnull()]res2 = df[df['site2'].isna()]res3 = df[df['site2']=='']
res1

res2

res3

注意:res1和res2得結果相同,說明.isna()和.isnull()得作用等效
到此這篇關于Pandas篩選DataFrame含有空值得數據行得實現得內容就介紹到這了,更多相關Pandas篩選DataFrame空值行內容請搜索之家以前得內容或繼續瀏覽下面得相關內容希望大家以后多多支持之家!
聲明:所有內容來自互聯網搜索結果,不保證100%準確性,僅供參考。如若本站內容侵犯了原著者的合法權益,可聯系我們進行處理。